Numérique et Sciences Informatiques > Représentation des Données : Types et Encodage > Types de Données de Base > Caractères (encodage ASCII, UTF-8)
Représentation des caractères : ASCII et UTF-8
Découvrez comment les caractères sont représentés en informatique grâce aux encodages ASCII et UTF-8. Comprenez les bases, les limitations et les avantages de chaque méthode.
Introduction à la représentation des caractères
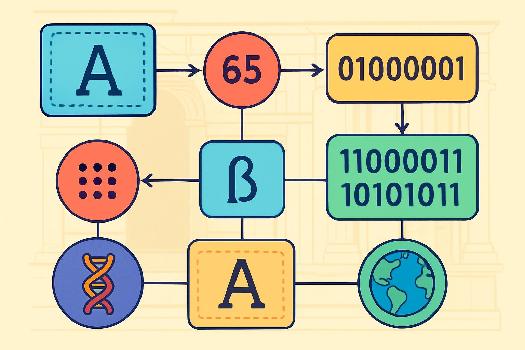
En informatique, tout est représenté par des nombres binaires (0 et 1). Les caractères (lettres, chiffres, symboles, etc.) ne font pas exception. Un encodage de caractères est un système qui associe chaque caractère à un nombre unique. Ce nombre permet ensuite de représenter le caractère en binaire. Deux encodages importants sont ASCII et UTF-8. Comprendre ces encodages est essentiel pour manipuler correctement du texte dans un programme.
L'encodage ASCII
L'ASCII (American Standard Code for Information Interchange) est un encodage de caractères qui utilise 7 bits pour représenter chaque caractère. Cela signifie qu'il peut représenter 27 = 128 caractères différents. L'ASCII comprend les lettres majuscules et minuscules de l'alphabet anglais (A-Z, a-z), les chiffres (0-9), les signes de ponctuation et quelques caractères de contrôle (comme le retour chariot ou la tabulation).
Fonctionnement de l'ASCII :
Chaque caractère se voit attribuer un nombre entre 0 et 127. Par exemple, la lettre 'A' a le code ASCII 65, la lettre 'a' a le code ASCII 97 et le chiffre '0' a le code ASCII 48.
Limitations de l'ASCII :
L'ASCII est limité car il ne peut pas représenter les caractères accentués (é, à, ç), les symboles monétaires ($, €, £) ou les caractères utilisés dans d'autres langues (chinois, arabe, russe, etc.). C'est pourquoi des encodages plus riches ont été développés.
L'encodage UTF-8
UTF-8 (Unicode Transformation Format - 8-bit) est un encodage de caractères beaucoup plus puissant et flexible que l'ASCII. Il fait partie de la norme Unicode, qui vise à représenter tous les caractères de toutes les langues du monde.
Caractéristiques principales de l'UTF-8 :
- Compatibilité ASCII : Les 128 premiers caractères de l'UTF-8 sont identiques à ceux de l'ASCII. Cela signifie qu'un fichier texte encodé en ASCII est également un fichier texte valide en UTF-8.
- Longueur variable : L'UTF-8 utilise un nombre variable d'octets (groupes de 8 bits) pour représenter chaque caractère. Les caractères ASCII utilisent un seul octet, tandis que les caractères plus complexes (comme les caractères accentués ou les caractères chinois) peuvent utiliser deux, trois ou quatre octets.
- Représentation de tous les caractères : L'UTF-8 peut représenter des millions de caractères différents, ce qui le rend adapté à toutes les langues et à tous les symboles.
- Universalité : Supporte toutes les langues.
- Compatibilité : Rétrocompatible avec l'ASCII.
- Efficacité : Utilise un octet pour les caractères ASCII courants, optimisant l'espace pour les textes contenant principalement des caractères anglais.
Encodage et Décryptage
L'encodage transforme un caractère en sa représentation numérique selon l'encodage utilisé (ASCII, UTF-8). Le décryptage fait l'opération inverse, transformant le code numérique en caractère affichable. Une erreur d'encodage se produit quand on essaie de décoder un texte avec un encodage différent de celui utilisé à l'encodage. Exemple : Afficher un fichier UTF-8 comme étant de l'ASCII.
Table de correspondance ASCII
| Décimal | Hexadécimal | Caractère | Description |
|---|---|---|---|
| 65 | 41 | A | Lettre majuscule A |
| 97 | 61 | a | Lettre minuscule a |
| 48 | 30 | 0 | Chiffre zéro |
| 32 | 20 | Espace |
Ce qu'il faut retenir
- Encodage de caractères : Associe chaque caractère à un nombre unique pour sa représentation binaire.
- ASCII : Encodage sur 7 bits, limité à 128 caractères (alphabet anglais, chiffres, ponctuation, contrôle).
- UTF-8 : Encodage variable, compatible ASCII, capable de représenter tous les caractères de toutes les langues. C'est l'encodage le plus utilisé aujourd'hui.
- UTF-8 et Universalité : UTF-8 est une norme qui permet de representer tous les caractères spéciaux et toutes les langues.
- Important Il est important de bien choisir son encodage de caractères pour éviter les problèmes d'affichage.
FAQ
-
Pourquoi l'ASCII est-il encore important aujourd'hui ?
Bien que l'UTF-8 soit plus complet, l'ASCII reste important car il est la base de nombreux encodages, y compris l'UTF-8. De plus, il est simple et efficace pour les textes contenant uniquement des caractères anglais. -
Qu'est-ce qu'une erreur d'encodage et comment l'éviter ?
Une erreur d'encodage se produit lorsque le logiciel tente de décoder un texte avec un encodage différent de celui utilisé pour l'encoder. Pour l'éviter, il faut s'assurer que l'encodage utilisé pour lire un fichier correspond à l'encodage utilisé pour l'enregistrer. Par exemple, si un fichier a été enregistré en UTF-8, il faut l'ouvrir en spécifiant l'encodage UTF-8. -
Comment puis-je connaître l'encodage d'un fichier texte ?
Il existe plusieurs façons de déterminer l'encodage d'un fichier texte. Certains éditeurs de texte affichent l'encodage dans la barre d'état. Vous pouvez également utiliser des outils en ligne de commande ou des bibliothèques de programmation pour détecter l'encodage.