Numérique et Sciences Informatiques > Représentation des Données : Types et Encodage > Structures de Données Élémentaires > Chaînes de caractères (manipulation, encodage)
Chaînes de caractères : Manipulation et Encodage
Explorez la manipulation et l'encodage des chaînes de caractères, une notion fondamentale en NSI. Découvrez les opérations courantes, les méthodes d'encodage et les pièges à éviter.
Introduction aux chaînes de caractères
Une chaîne de caractères, en informatique, est une séquence ordonnée de caractères. Ces caractères peuvent être des lettres (majuscules ou minuscules), des chiffres, des symboles de ponctuation ou d'autres symboles spéciaux. En Python, par exemple, les chaînes de caractères sont immuables, ce qui signifie qu'une fois créée, on ne peut pas modifier directement un caractère à l'intérieur de la chaîne. On doit créer une nouvelle chaîne si on veut changer quelque chose. Les chaînes de caractères sont essentielles pour représenter et manipuler du texte dans les programmes.
Manipulation des chaînes de caractères
De nombreuses opérations permettent de manipuler les chaînes de caractères. Voici quelques exemples courants:
- Concaténation: Joindre deux chaînes ensemble. En Python, on utilise l'opérateur
+. Exemple :'Bonjour' + ' ' + 'le monde'donne'Bonjour le monde'. - Extraction de sous-chaînes (slicing): Récupérer une partie d'une chaîne. On utilise les indices entre crochets
[]. Exemple :'Python'[0:3]donne'Pyt'. - Recherche: Trouver la position d'une sous-chaîne dans une chaîne. On peut utiliser la méthode
find(). Exemple :'NSI est cool'.find('cool')renvoie 7 (l'indice de début de 'cool'). - Remplacement: Remplacer une sous-chaîne par une autre. On utilise la méthode
replace(). Exemple :'Bonjour'.replace('jour', 'soir')donne'Bonsoir'. - Conversion Majuscules/Minuscules: Transformer une chaîne en majuscules (
upper()) ou en minuscules (lower()). Exemple :'Python'.upper()donne'PYTHON'. - Suppression des espaces: Supprimer les espaces en début et fin de chaîne (
strip()). Exemple :' Bonjour '.strip()donne'Bonjour'. - Longueur d'une chaîne: On utilise la fonction
len()pour connaître le nombre de caractères. Exemple:len('Bonjour')donne 7.
chaine = ' Python est un langage puissant '
chaine_modifiee = chaine.strip().upper().replace('PUISSANT', 'GÉNIAL')
print(chaine_modifiee) # Affiche: PYTHON EST UN LANGAGE GÉNIAL
Encodage des chaînes de caractères
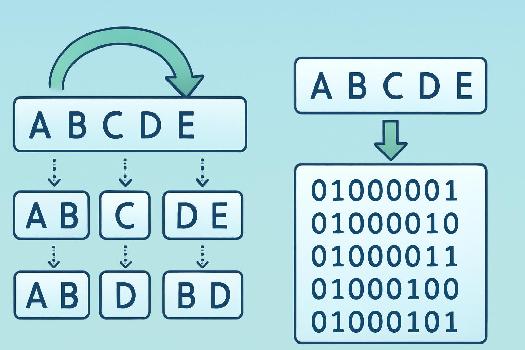
L'encodage consiste à représenter les caractères d'une chaîne sous forme de nombres binaires, compréhensibles par l'ordinateur. Différents standards d'encodage existent:
- ASCII (American Standard Code for Information Interchange): Un des plus anciens, il représente 128 caractères (lettres non accentuées, chiffres, symboles de ponctuation, caractères de contrôle) sur 7 bits. Limité pour les langues avec des caractères spéciaux.
- UTF-8 (Unicode Transformation Format - 8-bit): L'encodage le plus couramment utilisé aujourd'hui. Il peut représenter tous les caractères Unicode (plus d'un million de caractères). Il est compatible avec ASCII pour les 128 premiers caractères. C'est un encodage à taille variable: les caractères les plus courants sont codés sur 1 octet, les autres sur plusieurs octets.
- UTF-16: Un autre encodage Unicode, utilisant 16 bits (ou plus) par caractère.
- ISO-8859-1 (Latin-1): Une extension de ASCII, permettant de représenter certains caractères accentués utilisés dans les langues européennes occidentales.
Exemple de changement d'encodage en Python
En Python, on peut convertir une chaîne d'un encodage à un autre en utilisant les méthodes encode() et decode().
chaine = 'Ceci est une chaîne avec des accents : éàç'.encode('utf-8')
print(chaine)
chaine_decodee = chaine.decode('utf-8')
print(chaine_decodee)
Dans cet exemple, on encode la chaîne en UTF-8 puis on la décode pour revenir à la chaîne originale. Si on essaie de la décoder avec un encodage incorrect, on obtiendra une erreur ou des caractères incorrects.
Pièges courants et bonnes pratiques
- Confusion des encodages: Toujours vérifier l'encodage des fichiers et des données que vous manipulez. Utiliser UTF-8 par défaut pour une meilleure compatibilité.
- Immutable: Se rappeler que les chaînes sont immuables. Les opérations de modification créent de nouvelles chaînes.
- Erreurs d'index: Attention aux erreurs d'index lors de l'extraction de sous-chaînes. Les indices commencent à 0.
- Gestion des exceptions: Prévoir des mécanismes de gestion des exceptions (try...except) pour les erreurs d'encodage et de décodage.
- Normalisation des chaînes: Avant de comparer des chaînes, il peut être utile de les normaliser (par exemple, en les mettant en minuscules et en supprimant les accents) pour éviter les problèmes de casse et de différences de représentation.
Ce qu'il faut retenir
- Une chaîne de caractères est une séquence ordonnée de caractères immuable.
- Les opérations courantes incluent la concaténation, l'extraction de sous-chaînes, la recherche, le remplacement et la conversion majuscules/minuscules.
- L'encodage représente les caractères sous forme binaire. UTF-8 est l'encodage le plus couramment utilisé.
- Choisir le bon encodage est essentiel pour éviter les erreurs d'affichage.
- En Python, utilisez
encode()etdecode()pour changer l'encodage. - Soyez attentif aux erreurs d'index, à l'immuabilité des chaînes et à la gestion des exceptions liées à l'encodage.
FAQ
-
Quelle est la différence entre ASCII et UTF-8?
ASCII est un encodage limité à 128 caractères, tandis que UTF-8 peut représenter tous les caractères Unicode, ce qui le rend compatible avec la plupart des langues. -
Pourquoi est-il important de connaître l'encodage d'un fichier texte?
Si vous ne connaissez pas l'encodage, vous risquez d'afficher des caractères incorrects ou de rencontrer des erreurs lors de la lecture du fichier. L'application que vous utilisez doit interpréter correctement les bytes pour afficher le texte comme l'auteur l'a écrit. -
Comment convertir une chaîne de caractères en majuscules en Python?
Utilisez la méthodeupper()sur la chaîne. Par exemple:'bonjour'.upper()renvoie'BONJOUR'.