Numérique et Sciences Informatiques > Représentation des Données : Types et Encodage > Types de Données de Base > Caractères (encodage ASCII, UTF-8)
ASCII étendu et problèmes d'encodage de caractères
Explorez l'ASCII étendu et comprenez les problèmes liés aux différents encodages de caractères et à leur impact sur l'affichage du texte.
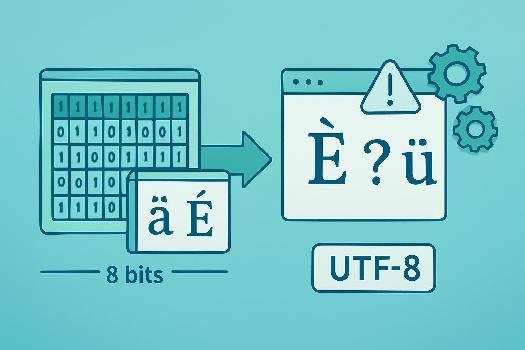
L'ASCII étendu
L'ASCII étendu, également appelé ASCII 8 bits, est une extension de l'ASCII original (7 bits). Il utilise un bit supplémentaire, portant la capacité totale à 28 = 256 caractères. Les 128 premiers caractères (0-127) restent identiques à l'ASCII standard. La plage 128-255 est utilisée pour représenter des caractères supplémentaires, tels que les caractères accentués, les symboles monétaires et certains caractères graphiques. Cependant, il n'existe pas qu'un seul standard pour l'ASCII étendu. Différents ensembles de caractères (appelés *pages de code*) ont été développés, chacun assignant des caractères différents aux codes 128-255. Par exemple, la page de code 850 est couramment utilisée en Europe occidentale.
Problèmes d'encodage de caractères
Le fait qu'il existe plusieurs pages de code ASCII étendu est à l'origine de nombreux problèmes d'encodage. Si un texte est encodé avec une page de code particulière et décodé avec une page de code différente, les caractères de la plage 128-255 seront affichés incorrectement. Cela peut entraîner l'apparition de caractères étranges ou illisibles à la place des caractères accentués ou des symboles attendus. Ces problèmes sont de moins en moins présent du fait de l'universalisation de UTF-8.
Exemple concret de problème d'encodage
Imaginons un fichier texte contenant le mot *été*. Si ce fichier est encodé avec la page de code 850, le caractère *é* sera représenté par le code 130. Si vous ouvrez ce fichier avec un éditeur de texte qui utilise la page de code 437 (une page de code courante aux États-Unis), le code 130 sera interprété comme un autre caractère (par exemple, un symbole graphique). Vous verrez donc un caractère incorrect à la place du *é*.
Pourquoi l'UTF-8 résout ces problèmes
UTF-8 résout ces problèmes car il utilise un seul encodage standard pour tous les caractères. Il n'y a pas de pages de code différentes à prendre en compte. Un même code UTF-8 représentera toujours le même caractère, quel que soit le système ou le logiciel utilisé. Cela garantit une représentation cohérente du texte sur toutes les plateformes.
Importance de la déclaration d'encodage
Lors de la création de fichiers HTML ou XML, il est crucial de déclarer l'encodage utilisé. Cela permet au navigateur ou à l'interpréteur XML de savoir comment interpréter les caractères. Pour UTF-8, on ajoute la balise <meta charset="UTF-8"> dans la section <head> du fichier HTML. Pour les fichiers XML, on utilise l'attribut encoding dans la déclaration XML : <?xml version="1.0" encoding="UTF-8"?>
Ce qu'il faut retenir
- ASCII étendu : Utilise 8 bits (256 caractères) mais n'est pas standardisé. Différentes pages de code existent.
- Problèmes d'encodage : L'incompatibilité des pages de code entraîne des erreurs d'affichage des caractères.
- UTF-8 : Résout ces problèmes grâce à un encodage unique et universel.
- Déclaration d'encodage : Indiquer l'encodage utilisé dans les fichiers HTML et XML est essentiel pour un affichage correct.
- UTF-8 est la solution recommandée Utiliser UTF-8 pour la representation des données.
FAQ
-
Comment puis-je convertir un fichier d'un encodage à un autre ?
De nombreux éditeurs de texte permettent de convertir un fichier d'un encodage à un autre. Vous pouvez également utiliser des outils en ligne de commande (comme `iconv` sous Linux) ou des bibliothèques de programmation. -
Est-ce que tous les logiciels prennent en charge l'UTF-8 ?
La plupart des logiciels modernes prennent en charge l'UTF-8. Cependant, certains anciens logiciels peuvent avoir des difficultés à gérer cet encodage. Dans ce cas, il peut être nécessaire de convertir le fichier dans un encodage plus ancien (mais cela peut entraîner une perte de caractères si le fichier contient des caractères non pris en charge par l'encodage cible). -
Pourquoi certains sites web affichent-ils des caractères étranges alors qu'ils sont censés utiliser UTF-8 ?
Cela peut être dû à plusieurs raisons :- Le serveur web n'envoie pas les bons en-têtes HTTP indiquant l'encodage UTF-8.
- La page web contient des caractères qui ne sont pas correctement encodés en UTF-8.
- Le navigateur web n'est pas configuré pour utiliser l'UTF-8 par défaut.