Numérique et Sciences Informatiques > Internet et le Web > Principes du Fonctionnement d'Internet > Architecture client-serveur
Architecture Client-Serveur : Le Modèle Fondamental du Web
Découvrez l'architecture client-serveur, le modèle qui sous-tend le fonctionnement d'Internet. Comprenez comment les clients (navigateurs) interagissent avec les serveurs pour accéder aux ressources web. Ce guide complet est conçu pour les élèves de lycée en spécialité NSI.
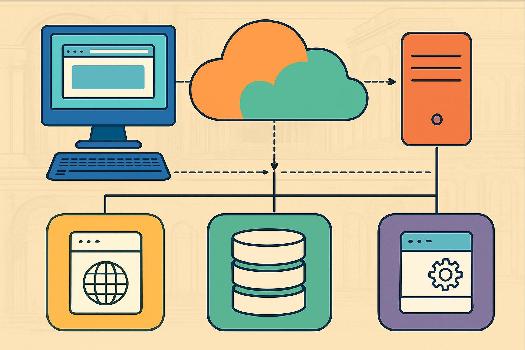
Qu'est-ce que l'Architecture Client-Serveur ?
L'architecture client-serveur est un modèle d'interaction informatique où un client envoie des requêtes à un serveur, qui traite ces requêtes et renvoie une réponse. Imaginez un restaurant : le client (vous) fait une demande au serveur (le serveur du restaurant), qui transmet la commande à la cuisine (le serveur informatique) et vous apporte ensuite votre plat (la réponse).
Client : Un client est une application ou un système qui initie une requête à un serveur. Dans le contexte du web, il s'agit généralement d'un navigateur web comme Chrome, Firefox, ou Safari.
Serveur : Un serveur est un programme ou un ordinateur qui attend et répond aux requêtes des clients. Il peut s'agir d'un serveur web (comme Apache ou Nginx) qui héberge des pages web, d'un serveur de base de données qui stocke des informations, ou d'un serveur de messagerie qui gère les emails.
Cette architecture permet de centraliser les ressources et de faciliter la gestion des services. Plusieurs clients peuvent accéder simultanément au même serveur.
Fonctionnement Détaillé
Voici les étapes clés du fonctionnement de l'architecture client-serveur dans le contexte du web :
- L'utilisateur entre une URL dans son navigateur. Par exemple,
https://www.exemple.com. - Le navigateur (client) envoie une requête HTTP au serveur. La requête contient des informations comme la méthode HTTP (GET, POST, etc.) et l'URL demandée.
- Le serveur reçoit la requête. Un serveur web, comme Apache ou Nginx, écoute les requêtes sur un port spécifique (généralement le port 80 pour HTTP et 443 pour HTTPS).
- Le serveur traite la requête. Il peut s'agir de récupérer une page HTML statique, d'exécuter un script côté serveur (PHP, Python, etc.), ou d'interroger une base de données.
- Le serveur renvoie une réponse HTTP au client. La réponse contient un code de statut (200 OK, 404 Not Found, etc.), des en-têtes HTTP (informations sur la réponse), et le contenu demandé (page HTML, image, etc.).
- Le navigateur reçoit la réponse et l'affiche. Le navigateur interprète le code HTML, télécharge les images, et exécute le code JavaScript pour rendre la page web interactive.
Exemple concret : Lorsque vous visitez un site de e-commerce et ajoutez un article à votre panier, votre navigateur (client) envoie une requête POST au serveur pour enregistrer cet ajout. Le serveur met à jour votre panier dans sa base de données et renvoie une confirmation.
Avantages de l'Architecture Client-Serveur
- Centralisation des données : Les données sont stockées et gérées sur le serveur, ce qui facilite leur sauvegarde, leur mise à jour et leur sécurité.
- Partage des ressources : Plusieurs clients peuvent accéder simultanément aux mêmes ressources sur le serveur.
- Évolutivité : Il est possible d'ajouter ou de remplacer des serveurs pour répondre à une demande croissante.
- Sécurité : La gestion de la sécurité est centralisée sur le serveur, ce qui permet de mieux protéger les données contre les accès non autorisés.
- Maintenance simplifiée : Les mises à jour et les correctifs peuvent être appliqués sur le serveur sans affecter les clients.
Types de Serveurs
Il existe différents types de serveurs, chacun ayant une fonction spécifique:
- Serveurs Web: Ils hébergent les sites web et répondent aux requêtes HTTP des navigateurs (ex: Apache, Nginx).
- Serveurs de Base de Données: Ils stockent et gèrent les données (ex: MySQL, PostgreSQL, MongoDB).
- Serveurs de Fichiers: Ils permettent de stocker et de partager des fichiers (ex: FTP servers).
- Serveurs de Messagerie: Ils gèrent les emails (ex: SMTP, IMAP, POP3).
- Serveurs d'Application: Ils exécutent des applications côté serveur et fournissent des services aux clients (ex: Java EE servers, Node.js servers).
Les protocoles
Des protocoles de communication sont essentiels pour le bon fonctionnement de l'architecture client-serveur. Voici quelques exemples:
- HTTP (Hypertext Transfer Protocol): Utilisé pour la communication entre les navigateurs et les serveurs web.
- HTTPS (HTTP Secure): Version sécurisée de HTTP, utilisant le chiffrement pour protéger les données transmises.
- TCP/IP (Transmission Control Protocol/Internet Protocol): Suite de protocoles qui permet la communication sur Internet.
- FTP (File Transfer Protocol): Utilisé pour le transfert de fichiers entre un client et un serveur.
- SMTP (Simple Mail Transfer Protocol): Utilisé pour l'envoi d'emails.
- IMAP (Internet Message Access Protocol): Utilisé pour la réception d'emails et la gestion des boîtes aux lettres.
Ce qu'il faut retenir
- L'architecture client-serveur est un modèle où un client envoie des requêtes à un serveur qui les traite et renvoie une réponse.
- Le client est généralement un navigateur web, et le serveur peut être un serveur web, un serveur de base de données, etc.
- Les avantages de cette architecture incluent la centralisation des données, le partage des ressources, l'évolutivité, la sécurité et la maintenance simplifiée.
- Les protocoles de communication comme HTTP, HTTPS, et TCP/IP sont essentiels pour le fonctionnement de l'architecture client-serveur sur Internet.
- Il existe différents types de serveurs, chacun ayant une fonction spécifique (web, base de données, fichiers, messagerie, application).
FAQ
-
Quelle est la différence entre HTTP et HTTPS ?
HTTP (Hypertext Transfer Protocol) est le protocole standard pour la communication web. HTTPS (HTTP Secure) est une version sécurisée de HTTP qui utilise le chiffrement SSL/TLS pour protéger les données transmises entre le client et le serveur. HTTPS est essentiel pour les sites web qui traitent des informations sensibles, comme les données bancaires ou les informations personnelles. -
Qu'est-ce qu'une requête GET et une requête POST ?
Une requête GET est utilisée pour récupérer des données du serveur. Elle est généralement utilisée pour afficher une page web ou télécharger un fichier. Les paramètres de la requête sont inclus dans l'URL. Une requête POST est utilisée pour envoyer des données au serveur, par exemple pour soumettre un formulaire ou créer un nouvel enregistrement dans une base de données. Les paramètres de la requête sont inclus dans le corps de la requête, ce qui la rend plus sécurisée pour l'envoi d'informations sensibles.