Numérique et Sciences Informatiques > Algorithmique : Tris et Recherche > Algorithmes de Tri Efficaces > Tri rapide (Quicksort)
Tri Rapide (Quicksort) : Comprendre et Implémenter
Découvrez l'algorithme de tri rapide (Quicksort), un algorithme efficace et largement utilisé. Cette ressource détaille son fonctionnement, son implémentation et son analyse de complexité, le tout adapté aux élèves de lycée en Numérique et Sciences Informatiques.
Introduction au Tri Rapide
Le tri rapide (Quicksort) est un algorithme de tri basé sur le principe 'diviser pour régner'. Il est reconnu pour son efficacité en moyenne, ce qui en fait un choix populaire dans de nombreuses applications. L'idée principale est de partitionner le tableau en deux sous-tableaux autour d'un élément pivot, de telle sorte que tous les éléments inférieurs au pivot soient placés avant lui, et tous les éléments supérieurs soient placés après lui. Ensuite, les sous-tableaux sont triés récursivement.
Principe de Partitionnement
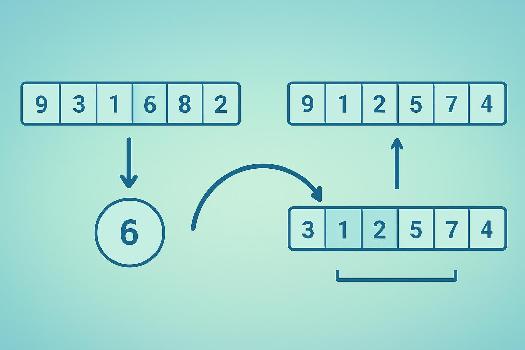
Le cœur du tri rapide est le processus de partitionnement. Il se déroule comme suit:
- Choisir un pivot: Sélectionnez un élément du tableau comme pivot. Le choix du pivot peut affecter significativement la performance de l'algorithme. Des stratégies courantes incluent choisir le premier élément, le dernier élément, ou un élément aléatoire.
- Réorganiser le tableau: Parcourez le tableau et comparez chaque élément au pivot. Les éléments inférieurs au pivot sont déplacés vers la gauche, et les éléments supérieurs sont déplacés vers la droite.
- Position finale du pivot: Une fois le partitionnement terminé, le pivot est à sa position finale dans le tableau trié.
[7, 2, 1, 6, 8, 5, 3, 4] et que l'on choisit 7 comme pivot. Après le partitionnement, on obtiendra un tableau similaire à [2, 1, 6, 5, 3, 4, 7, 8].Algorithme Récursif
Après le partitionnement, deux sous-tableaux sont créés : un contenant les éléments inférieurs au pivot, et l'autre contenant les éléments supérieurs au pivot. Le tri rapide est ensuite appliqué récursivement à ces deux sous-tableaux. Cette récursion se poursuit jusqu'à ce que les sous-tableaux aient une taille de 0 ou 1, auquel cas ils sont trivialement triés.
- Cas de base: Si le tableau a 0 ou 1 élément, il est déjà trié.
- Appel récursif: Appelez récursivement le tri rapide sur les deux sous-tableaux créés par le partitionnement.
Exemple d'Implémentation en Python
Voici un exemple d'implémentation du tri rapide en Python :
def quicksort(tableau):
if len(tableau) <= 1:
return tableau
pivot = tableau[len(tableau) // 2]
gauche = [x for x in tableau if x < pivot]
milieu = [x for x in tableau if x == pivot]
droite = [x for x in tableau if x > pivot]
return quicksort(gauche) + milieu + quicksort(droite)
tableau = [7, 2, 1, 6, 8, 5, 3, 4]
tableau_trie = quicksort(tableau)
print(tableau_trie) # Affiche [1, 2, 3, 4, 5, 6, 7, 8]
Analyse de Complexité
La complexité du tri rapide dépend du choix du pivot.
- Meilleur cas et cas moyen: O(n log n). Cela se produit lorsque le pivot divise le tableau en deux parties à peu près égales à chaque étape.
- Pire cas: O(n^2). Cela se produit lorsque le pivot est toujours le plus petit ou le plus grand élément du tableau. Par exemple, si le tableau est déjà trié et que le pivot est toujours le premier élément.
Stratégies d'Optimisation
Plusieurs techniques peuvent être utilisées pour optimiser le tri rapide :
- Choix du pivot: Choisir un pivot aléatoire ou la médiane de trois éléments peut réduire la probabilité du pire cas.
- Tri par insertion pour les petits tableaux: Pour les petits sous-tableaux, le tri par insertion peut être plus efficace que le tri rapide. On peut donc utiliser le tri par insertion lorsque la taille du sous-tableau est inférieure à un certain seuil.
- Optimisation de la récursion terminale (tail recursion optimization): Dans certains langages, la récursion terminale peut être optimisée pour éviter le débordement de pile.
Ce qu'il faut retenir
- Le tri rapide est un algorithme de tri basé sur le principe 'diviser pour régner'.
- Il partitionne le tableau autour d'un pivot et trie récursivement les sous-tableaux.
- Sa complexité est de O(n log n) en moyenne et O(n^2) dans le pire cas.
- Le choix du pivot est crucial pour la performance.
- Des optimisations existent pour améliorer son efficacité, comme le choix d'un pivot aléatoire et l'utilisation du tri par insertion pour les petits tableaux.
FAQ
-
Pourquoi le tri rapide est-il appelé 'rapide' si son pire cas est O(n^2)?
Bien que son pire cas soit O(n^2), le tri rapide a une complexité moyenne de O(n log n), et est souvent plus rapide en pratique que d'autres algorithmes O(n log n) en raison de facteurs constants plus faibles et d'une bonne localisation des données. -
Comment le choix du pivot affecte-t-il la performance du tri rapide?
Un mauvais choix de pivot (par exemple, toujours le plus petit ou le plus grand élément) peut conduire au pire cas, où le tri rapide a une complexité de O(n^2). Un bon choix de pivot (par exemple, un élément aléatoire ou la médiane) peut assurer que le tableau est divisé en parties à peu près égales à chaque étape, ce qui conduit à une complexité de O(n log n). -
Quand devrais-je utiliser le tri rapide plutôt que d'autres algorithmes de tri?
Le tri rapide est généralement un bon choix lorsque la performance est importante et que vous avez besoin d'un algorithme de tri en place. Cependant, si vous avez besoin d'une garantie de performance O(n log n) même dans le pire cas, vous devriez envisager d'autres algorithmes comme le tri fusion (Merge Sort).