Numérique et Sciences Informatiques > Algorithmique : Tris et Recherche > Algorithmes de Tri Élémentaires > Tri par insertion
Tri par Insertion : Analyse de Complexité et Optimisations
Explorez en profondeur la complexité du tri par insertion et découvrez des techniques d'optimisation pour améliorer ses performances dans des scénarios spécifiques.
Révision du Tri par Insertion
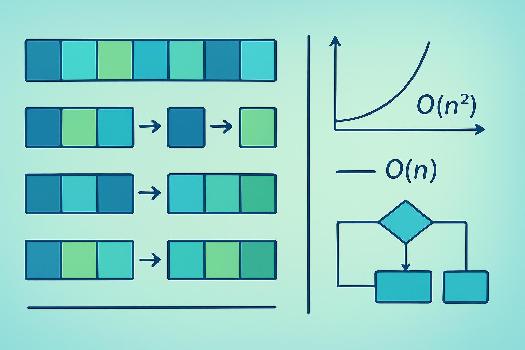
Avant de plonger dans l'analyse de complexité et les optimisations, rappelons brièvement le fonctionnement du tri par insertion. Il s'agit d'un algorithme itératif qui construit une sous-liste triée à partir du début du tableau. Pour chaque élément non trié, on le compare aux éléments de la sous-liste triée, on décale les éléments plus grands vers la droite, et on insère l'élément courant à sa position correcte.
Analyse de la Complexité Temporelle
L'analyse de la complexité temporelle du tri par insertion révèle des aspects importants :
- Cas le plus favorable : O(n). Si le tableau est déjà trié, la boucle interne (
while) ne s'exécute jamais, car chaque élément est immédiatement à sa place. On effectue simplement une seule passe sur le tableau (bouclefor). - Cas moyen : O(n²). En moyenne, pour chaque élément, on doit parcourir la moitié de la sous-liste triée pour trouver sa position. Cela conduit à une complexité quadratique.
- Cas le plus défavorable : O(n²). Si le tableau est trié en ordre inverse, chaque élément doit être comparé à tous les éléments précédents, ce qui nécessite le maximum de décalages.
Analyse de la Complexité Spatiale
Le tri par insertion est un algorithme en place, ce qui signifie qu'il ne nécessite qu'un espace mémoire constant supplémentaire. On n'a besoin que de quelques variables temporaires pour stocker l'élément à insérer (cle dans l'exemple précédent) et l'indice de la position courante (j). Par conséquent, la complexité spatiale est de O(1).
Optimisations Possibles
Bien que la complexité fondamentale du tri par insertion soit quadratique, certaines optimisations peuvent améliorer ses performances dans des cas spécifiques :
- Recherche dichotomique (binaire) : Au lieu de parcourir linéairement la sous-liste triée pour trouver la position d'insertion, on peut utiliser une recherche dichotomique. Cela réduit le nombre de comparaisons à O(log n) par élément, mais le nombre de décalages reste le même, ce qui ne change pas la complexité globale (O(n²)). Cependant, dans la pratique, cela peut apporter une légère amélioration.
- Utilisation du tri par insertion pour les petits sous-tableaux (Hybrid Sort) : Dans les algorithmes de tri plus complexes, comme le tri rapide (Quick Sort) ou le tri fusion (Merge Sort), on peut utiliser le tri par insertion pour trier les petits sous-tableaux. Ces algorithmes sont plus efficaces pour les grands ensembles de données, mais le tri par insertion peut être plus rapide pour les petits sous-problèmes. C'est une technique courante dans les implémentations optimisées de ces algorithmes.
Exemple d'Optimisation avec Recherche Dichotomique (Python)
Voici une implémentation du tri par insertion avec recherche dichotomique en Python :
def recherche_dichotomique(tableau, gauche, droite, cle):
if droite <= gauche:
return gauche if cle > tableau[gauche] else gauche + 1
milieu = (gauche + droite) // 2
if cle == tableau[milieu]:
return milieu + 1
elif cle > tableau[milieu]:
return recherche_dichotomique(tableau, milieu + 1, droite, cle)
else:
return recherche_dichotomique(tableau, gauche, milieu - 1, cle)
def tri_insertion_dichotomique(tableau):
n = len(tableau)
for i in range(1, n):
cle = tableau[i]
j = i - 1
# Trouver l'index où l'élément 'cle' doit être inséré
index = recherche_dichotomique(tableau, 0, j, cle)
# Déplacer les éléments à droite de l'index d'une position
while j >= index:
tableau[j + 1] = tableau[j]
j -= 1
# Insérer l'élément 'cle'
tableau[j + 1] = cle
return tableau
# Exemple d'utilisation
tableau = [5, 2, 4, 6, 1, 3]
tableau_trie = tri_insertion_dichotomique(tableau)
print(tableau_trie) # Output: [1, 2, 3, 4, 5, 6]
Comparaison avec d'Autres Algorithmes de Tri
Il est important de comparer le tri par insertion avec d'autres algorithmes de tri :
- Tri par sélection : Le tri par sélection a également une complexité de O(n²), mais il effectue moins d'échanges que le tri par insertion. Cependant, le tri par insertion est généralement plus rapide en pratique, surtout pour les données presque triées.
- Tri à bulles : Le tri à bulles est également un algorithme simple avec une complexité de O(n²). Il est généralement moins performant que le tri par insertion et le tri par sélection.
- Tri rapide (Quick Sort) et Tri fusion (Merge Sort) : Ces algorithmes ont une complexité de O(n log n) dans le cas moyen, ce qui les rend beaucoup plus efficaces pour les grands ensembles de données. Cependant, ils sont plus complexes à implémenter et peuvent avoir une complexité plus élevée dans le cas le plus défavorable (par exemple, O(n²) pour le tri rapide si le pivot est mal choisi).
Conclusion
Le tri par insertion est un algorithme simple et intuitif, particulièrement adapté aux petits ensembles de données ou aux données presque triées. Bien que sa complexité quadratique le rende moins performant que d'autres algorithmes pour les grands ensembles de données, sa simplicité et son efficacité pour les petits problèmes en font un outil utile dans certaines situations. Les optimisations, comme l'utilisation de la recherche dichotomique ou son intégration dans des algorithmes hybrides, peuvent améliorer ses performances dans des cas spécifiques.
Ce qu'il faut retenir
- La complexité du tri par insertion est de O(n²) dans le cas moyen et le pire, et O(n) dans le meilleur des cas (tableau déjà trié).
- Il est un algorithme de tri en place, avec une complexité spatiale de O(1).
- Des optimisations, comme l'utilisation de la recherche dichotomique, peuvent légèrement améliorer ses performances.
- Il est souvent utilisé comme sous-routine dans des algorithmes de tri plus complexes pour trier de petits sous-tableaux.
- Bien que simple, il est moins performant que les algorithmes de tri en O(n log n) pour les grands ensembles de données.
FAQ
-
L'utilisation de la recherche dichotomique améliore-t-elle significativement la performance du tri par insertion ?
Non, bien que la recherche dichotomique réduise le nombre de comparaisons à O(log n) par élément, le nombre de décalages reste de O(n), ce qui ne change pas la complexité globale de O(n²). Cependant, dans la pratique, on peut observer une légère amélioration des performances. -
Pourquoi le tri par insertion est-il parfois utilisé dans les algorithmes de tri hybrides ?
Le tri par insertion est efficace pour trier de petits ensembles de données. Les algorithmes de tri hybrides utilisent le tri par insertion pour trier les petits sous-tableaux, car il est plus rapide que les algorithmes plus complexes pour ces petits problèmes. -
Existe-t-il des cas où le tri par insertion est préférable au tri rapide ?
Oui, le tri par insertion est préférable lorsque le tableau est petit (moins de quelques dizaines d'éléments) ou lorsque les données sont presque triées. Dans ces cas, sa simplicité et sa faible surcharge peuvent le rendre plus rapide que le tri rapide.