SVT > L'Hérédité et la Génétique > La Génétique Moléculaire > Le code génétique
Le Code Génétique: Décryptage du Langage de la Vie
Explorez le code génétique, le langage universel qui traduit l'information génétique en protéines. Découvrez sa nature, ses propriétés, son fonctionnement et son importance cruciale pour la vie.
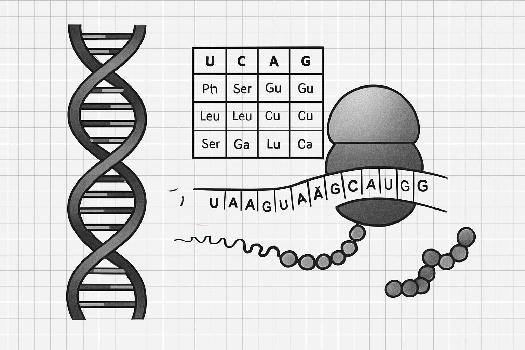
Qu'est-ce que le Code Génétique?
Le code génétique est un ensemble de règles qui définit comment l'information contenue dans le matériel génétique (ADN ou ARN) est traduite en protéines par les cellules vivantes. C'est un dictionnaire moléculaire qui associe des séquences de trois nucléotides (codons) à des acides aminés spécifiques, les briques de construction des protéines. Imaginez que c'est comme un langage, où chaque mot (codon) représente une lettre (acide aminé) dans la construction d'un message (protéine).
La Nature Triplet du Code Génétique
Le code génétique est basé sur des triplets de nucléotides, appelés codons. Chaque codon correspond à un acide aminé particulier, ou à un signal d'arrêt (codon stop). Puisqu'il y a quatre nucléotides (Adénine (A), Guanine (G), Cytosine (C), Thymine (T) dans l'ADN et Uracile (U) dans l'ARN), il existe 43 = 64 codons possibles. Ces 64 codons codent pour 20 acides aminés différents et les signaux stop. Cela signifie que plusieurs codons peuvent coder pour le même acide aminé, une propriété appelée dégénérescence du code génétique.
Exemple: Les codons CUU, CUC, CUA et CUG codent tous pour la Leucine.
Caractéristiques Clés du Code Génétique
Le code génétique présente plusieurs caractéristiques importantes :
- Universalité: Il est presque universel, c'est-à-dire qu'il est utilisé par tous les organismes vivants (bactéries, plantes, animaux...). Quelques rares exceptions existent, notamment dans les mitochondries de certains organismes.
- Dégénérescence (Redondance): La plupart des acides aminés sont codés par plusieurs codons. Cela réduit l'impact des mutations ponctuelles sur la séquence des protéines.
- Non-chevauchement: Les codons sont lus de manière consécutive, sans chevauchement.
- Non-ambiguïté: Chaque codon spécifie un seul acide aminé.
- Lecture avec cadre de lecture: Le ribosome lit l'ARNm en commençant à un codon de start (AUG) et en continuant en groupe de trois nucléotides jusqu'à rencontrer un codon de stop.
Codons Start et Stop
Le code génétique comprend des codons spécifiques pour initier et terminer la traduction.
- Codon Start (AUG): Le codon AUG, qui code également pour l'acide aminé méthionine, signale le début de la traduction. C'est en quelque sorte le signal de départ pour la synthèse protéique.
- Codons Stop (UAA, UAG, UGA): Ces codons ne codent pour aucun acide aminé. Ils signalent la fin de la traduction, indiquant à la machinerie cellulaire de relâcher la protéine nouvellement synthétisée.
La Traduction: Du Code Génétique à la Protéine
La traduction est le processus par lequel l'information génétique contenue dans l'ARNm est utilisée pour synthétiser une protéine. Elle se déroule dans les ribosomes et implique l'ARN de transfert (ARNt).
Étapes clés de la traduction :
- Initiation: Le ribosome se lie à l'ARNm et localise le codon start (AUG).
- Élongation: Les ARNt, portant chacun un acide aminé spécifique, se lient aux codons correspondants sur l'ARNm. Les acides aminés sont liés entre eux par des liaisons peptidiques, formant une chaîne polypeptidique.
- Terminaison: Lorsque le ribosome rencontre un codon stop, la traduction s'arrête et la protéine est libérée.
Mutations et Code Génétique
Les mutations, ou changements dans la séquence d'ADN, peuvent avoir divers effets sur le code génétique et les protéines qu'il code.
Types de mutations :
- Mutations ponctuelles : Changement d'un seul nucléotide. Elles peuvent être :
- Silencieuses : Pas de changement de l'acide aminé (grâce à la redondance du code).
- Missense : Changement d'acide aminé.
- Nonsense : Introduction d'un codon stop prématuré, menant à une protéine tronquée et souvent non fonctionnelle.
- Mutations par décalage du cadre de lecture : Insertion ou délétion d'un nombre de nucléotides qui n'est pas un multiple de trois. Cela modifie complètement le cadre de lecture après la mutation, menant à une protéine totalement différente.
Ce qu'il faut retenir
- Le code génétique est un ensemble de règles qui traduisent l'information génétique en protéines.
- Il est basé sur des triplets de nucléotides appelés codons.
- Il est presque universel, dégénéré, non-chevauchant et non-ambigu.
- Il comprend des codons start (AUG) et stop (UAA, UAG, UGA).
- La traduction est le processus par lequel l'ARNm est utilisé pour synthétiser une protéine.
- Les mutations peuvent affecter le code génétique et les protéines.
FAQ
-
Pourquoi dit-on que le code génétique est dégénéré?
On dit que le code génétique est dégénéré car plusieurs codons différents peuvent coder pour le même acide aminé. Cette redondance permet de minimiser les effets des mutations ponctuelles sur la séquence des protéines. -
Qu'est-ce qu'un codon stop?
Un codon stop est un codon qui signale la fin de la traduction. Il n'est associé à aucun acide aminé. Les codons stop sont UAA, UAG et UGA. -
Quel est le rôle de l'ARNt dans la traduction?
L'ARNt (ARN de transfert) est une molécule d'ARN qui transporte un acide aminé spécifique vers le ribosome lors de la traduction. Chaque ARNt possède un anticodon qui se lie à un codon spécifique sur l'ARNm.